Reinventing the Data Platform in the Cloud
In our first story we pointed out which architectural aspects and paradigms are crucial for a sucessful data platform. The data platform described there is located on-prem and makes heavy use of the Hadoop ecosystem. However, with the advent of the public cloud, focus shifts towards designing and building data platforms in the cloud. Public cloud is now much more than simply being able to get compute and storage capacity. A wide variety of services now is offered there that covers also anything related to data. Architecture discussions are now also increasingly happening around what are best practices to design a data platform in the cloud.
A new approach?
Some claim that everything should be changed in the way how a data platform is designed in the cloud. Others are keen on simply moving the entire on-prem pipelines to servers in the cloud. Some argue that the Data Warehouse (DWH) will become obsolete and replaced by cloud Data Lakes, others tell the exact opposite. People are also trying to understand how to make best use of the tools offered in the cloud for Machine Learning or real-time analytics. In this article we propose a logical architecture for a cloud data platform, discuss how the Data Lake and DWH interact there and also point out how the cloud data platform can support Machine Learning use cases.
The story starts — as always — with architectural paradigms. It’s important to note that although some architectural building blocks and many technologies do change as compared to on-prem data platform, the case for a layered architecture still remains. This is the most important architecture paradigm that prevents your data platform from falling into chaos due to a missing separation of concerns — something we previously referred to as spaghetti architecture.
Before discussing this paradigm and others in more detail, let’s look at what the cloud data platform actually could look like. It does not show specific technologies or data flows, instead it depicts crucial layers and capabilities the cloud data platform should offer:
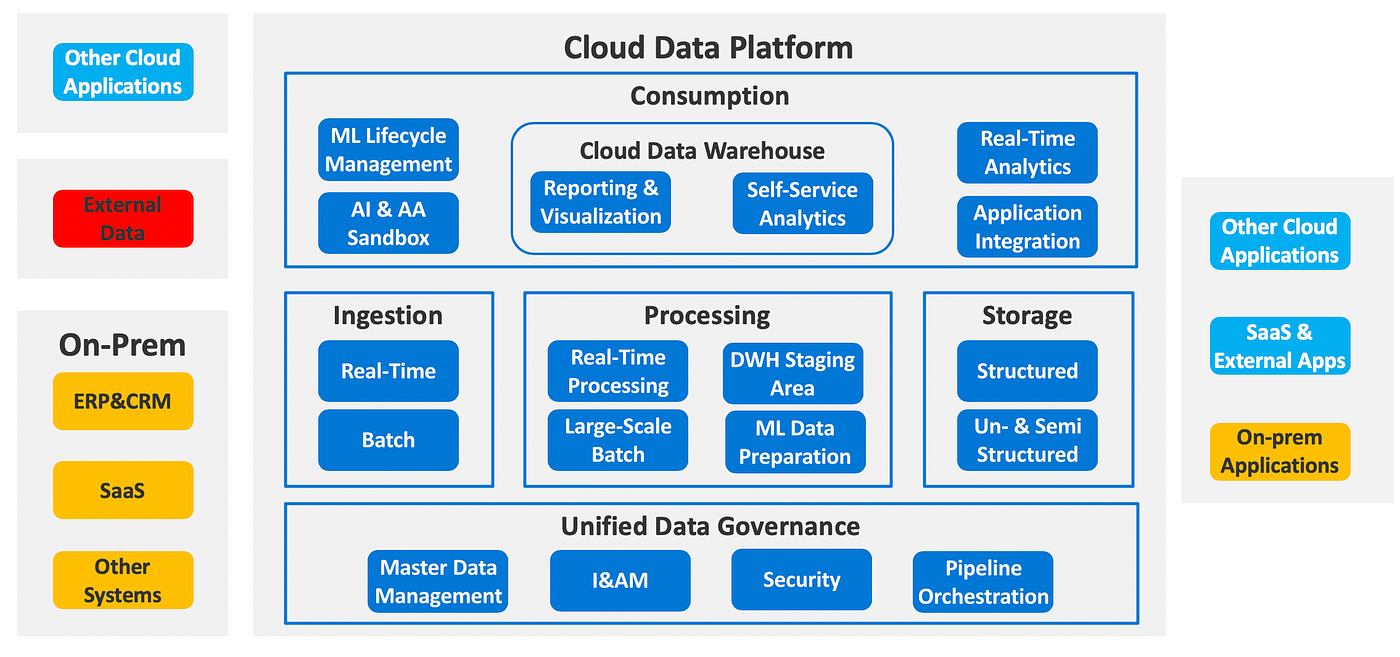
The foundation of the Cloud Data Platform
As you can see, there are three core pillars: Ingestion, Processing and Storage. They form the backbone of the data platform.
In Ingestion, data can be loaded into the cloud data platform both in batch and streaming mode. This layer has to be able to capture data from on-prem applications (both legacy and modern), other cloud applications, databases, SaaS and external data. Thus it is possible to give access to interested data users to all types and sources of data across the enterprise enabling data democratization there. Although we would argue that it makes sense to opt for a streaming approach wherever possible, batch ingestion also has to be supported since many sources are available only in batch mode (e.g. daily provisioning of files from an external data provider). The reason to choose streaming over batch ingestion if it’s possible is that to get the same data in streaming mode after you’ve built a batch ingestion pipeline almost surely means that you’ll have to change the pipeline completely. On the other hand, a streaming ingestion pipeline can also feed a batch processing pipeline. For example you can have a Kafka topic where data arrives in real-time, but a Spark batch job retrieves and processes newly arriving data only every three hours.
The Processing layer is the heart of the cloud data platform. Here data can be processed in order to gain insights from it and deliver business value to your enterprise. As the ingestion layer delivers data in both streaming and batch modes, it has to be able to process data in these two ways. Since the cloud offers sheer endless scalability, this is the place for large scale data processing, which often is the foundation for preparing data for training of complicated Machine Learning models. Finally, it’s possible to use this layer as staging area for the Cloud DWH — we will talk more about this later.
The Storage layer persists data continuously. It has to be able to store data in all formats that is available in sources. This means it’s possible to store structured data (like for example data from a relational database), semi-structured data (like JSON documents in a document-oriented NoSQL database) and unstructured data (e.g. images in form of files stored in object storage). Data can be stored as an intermediate step in a processing pipeline here, for being retrieved by other applications from outside the cloud data platform or for archival purposes.
An additional so-called Unified Data Governance layer spans the entire cloud data platform. It offers capabilities like Identity&Access Management (IAM) and security controls to ensure that only those people who are allowed to can access the data platform at all. It ensures that those people who are authorized to access the data platform only see the data they are allowed to see and enforces compliance with data protection laws like GDPR. Besides this, it also offers tools for orchestrating and coordinating the many different data pipelines you’ll probably have in your cloud data platform. Finally, knowing what data you have where in your data platform and offering mechanisms for ensuring data quality in your pipelines is the job of master data management tools.
Using the Cloud Data Platform
The layer where the actual users of the data platform will be interacting with it is called Consumption layer. Here a variety of services is offered and it also depends on what your actual use cases are. What unites these services is that this is the part of the cloud data platform is where its users are able to get (or consume) the business value from it. In our reference architecture we cover some typical use cases we’ve seen to be implemented on Cloud Data Platforms: Machine Learning, the Cloud DWH and real-time analytics.
Let’s start with Machine Learning. We’ve mentioned that the processing layer is used for preparing data and training Machine Learning models. This is a good choice for the cloud as such a use case typically requires lots of data and compute power. The cloud with its offering of elastic scalability can easily cover such requirements. In addition, these processes usually are batch-oriented, which means that you can spin up a distributed compute cluster (with e.g. Spark) and after the data processing is done tear it down again. This helps saving compute costs as compared to on-prem where you continuously need to provision the required resources even if you don’t need them at a specific moment. Whilst this happens inside the processing layer, it’s only one of the typical phases in the Machine Learning lifecycle. The consumption layer offers tools to have a holistic end-to-end experience for your data science teams — besides being able to prepare data and train models, they can also automatically deploy trained models, monitor their performance and also feed back the results of the models into systems outside the data platform (we’ll talk more about application integration shortly). Also designing new models and doing exploratory analytics on data in a sandbox environment is offered in the consumption layer of the cloud data platform.
If your Machine Learning model has scored, you probably want to loop back this results into your business applications so that your business can get the value out of your Machine Learning initiatives. This is where application integration appears — the consumption layer of your cloud data platform should be able to integrate with outside systems. This happens either through exposing APIs, which these systems can connect into or loading data into data stores inside these systems through data processing components like Spark or other integration tools. In this case data storage can be a relational database, a NoSQL database or a distributed message queue like Kafka.
Application integration also plays a vital role for real-time analytics. In most cases people on the business side don’t use dashboards that change in real-time. Instead it’s required that the results from a real-time analytics pipeline is fed in real-time back into a business system. Imagine a retailer that has detected that a competitor is running a pricing campaign right now for a specific product category or subset. Instead of manually reacting to this — an approach that would just take up valuable time — you can automatically trigger a pricing campaign of your own in real-time thus making sure your competitor won’t get all the revenue and you are left sitting on your stock.
However, sometimes people are looking for real-time (or near-real-time dashboards). These are also a capability offered in the consumption layer of the cloud data platform. Together with other dashboards for data visualization and KPI reporting they form the cloud Data Warehouse. The cloud DWH is the central touchpoint for the business users with the cloud data platform. They can use Self-Service BI tools to explore datasets and derive business insights from them directly without engineers having to build specific pipelines first. It’s also the point where data analysts can run SQL queries on pre-processed data. You could also use the cloud DWH as the place where you do the (pre-) processing of your data. However in our experience in many cases it’s a rather expensive approach to utilizing the cloud data platform. The reason is that compute resources for example for producing reports or aggregating data is still quite expensive in the cloud DWH. Instead it’s better to make usage of the distributed compute resources offered in the processing layer of the cloud data platform. Here you can run hourly or daily batch processing of your data for producing data that is required for the reports inside the cloud DWH. In many cases spinning up a Spark cluster to crunch data that has arrived during the latest batch period is a very good choice both architecturally and from a cost-point of view — you can simply delete the cluster once you’re done with the processing. The results of this processing can not only be sent to the cloud DWH but also to other areas in the storage layer for usage by your data science teams or another data pipeline on your cloud data platform.
And this finally is the part where the relationship of cloud DWH and Data Lake is discussed. Obviously you still have a DWH although with some changes to the architecture as compared to how you’ve designed the DWH in on-prem environments. And you also have a Data Lake. Now you might ask yourself where’s the Data Lake, it hasn’t been mentioned in the architecture? The Data Lake is primarily made up of the three layers ingestion, processing and storage — generally speaking it’s the combination of the capabilities these three layers do offer. So the bottom line is that the Data Lake and the cloud DWH don’t get replaced by either of them. Instead they form a crucial combination for your cloud data platform’s success. The cloud DWH is the core entry-point for your business users whilst the Data Lake covers the compute-intensive processing of data so that your overall total cost of ownership (TCO) is lower as compared to an on-prem data platform.
Another paradigm presented in our first story on Data Lakes is that building a Data Lake in a conventional way by dumping any data you have to the data platform is still a bad idea. Just because you now have endless scalability for storage on the cloud this doesn’t mean you should load everything there. Instead it is better to load just the data you need for specific use cases that are well defined and have an added business value — build a Data Hub to avoid your Data Lake becoming a Data Swap.
Managed Services
Eventually we’d like to point out another important paradigm for the design of cloud data platforms: Embrace Managed Services. Where it is possible you should try to use them — be it a Managed Service offered by the cloud provider or your software vendor. This is because especially distributed systems are difficult to operate and keep stable. Often entire legions of DevOps engineers are required to do that. It’s a much better usage of your DevOps teams and their life time to let them focus on more interesting issues related to the business requirements of your data pipelines than on heavy-lifting tasks. Cloud providers and software vendors know their systems best and they will be able to offer you a much more stable experience of their products than if you would only use the underlying infrastructure offered by the cloud provider and let your DevOps team still do the entire system operations work. This will make both your DevOps team and the users of the cloud data platform much happier as the entire data platform will be much more stable and you’ll have much less incidents related to platform issues.
We hope that you find our architectural paradigms and concepts useful when designing your own cloud data platform. In our next story we will describe how we built a part of our cloud data platform with data from SalesForce going into the Google Cloud Platform.
About the Authors: Mark and Vladimir Elvov work in different functions in Data Architecture. New technologies are our core passion — using architecture to drive their adoption is our daily business. In this blog we write about everything that is related to Big Data and Cloud technologies: From High-Level strategies via use cases down into what we’ve seen in the front-line trenches of production and daily operations work.